
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- python
- 파이썬
- 7785
- 구조적 데이터
- 10825
- 경쟁적 전염
- 넷플릭스 추천 시스템
- 3085
- 18405
- 7662
- 컨텐츠 기반 필터링
- 특정 거리의 도시 찾기
- 추천과 검색
- 14620
- hannanum
- 18352
- Pypy3
- google dialogflow
- 1620
- 추천 시스템의 한계
- 앤드류 응
- 1259
- 추천시스템
- 유튜브 추천 시스템
- 문자열반전
- 백준
- 협업 필터링
- 추천 시스템
- 유사도
- 알고리즘
- Today
- Total
Kowal's Igloo
🍎 [딥러닝 2단계] 5. 하이퍼파라미터 튜닝 본문
하이퍼파라미터 종류 (중요도순)
- 학습률( α )
- 모멘텀(Momentum) 알고리즘의 β
- 은닉 유닛의 수
- 미니배치 크기
- 은닉층의 갯수
- 학습률 감쇠(learning rate decay) 정도
- 아담(Adam) 알고리즘의 β1, β2, ϵ
- 튜닝 프로세스
1. 무작위 접근 방식
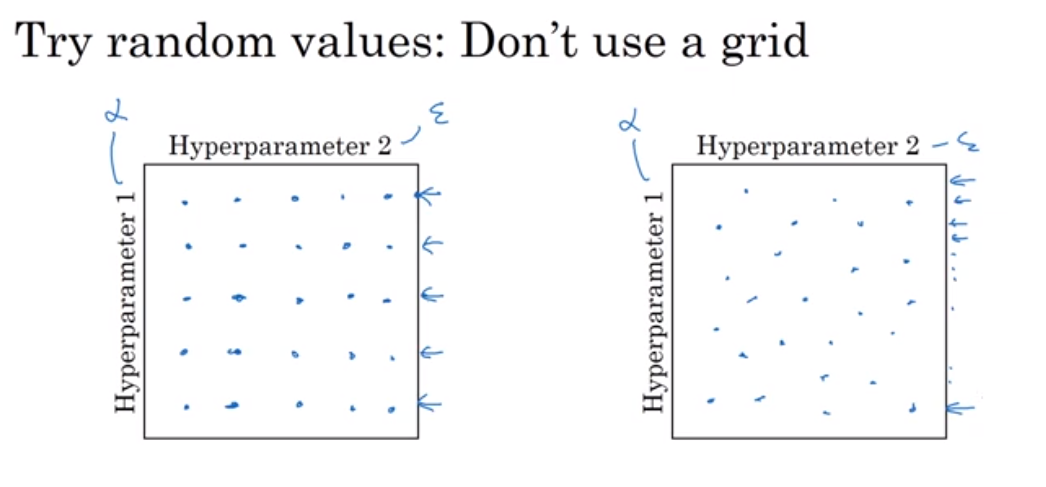
과거에는 왼쪽 방법을 사용했다. 이 방법은 데이터의 수가 적을 때 쓰기 좋다.
현재 딥러닝에서는 오른쪽과 같이 무작위로 선택된 지점의 값을 쓴다. 어떤 값이 좋을지 미리 알 수 없기 때문이다.
예를 들어 α와 ϵ을 튜닝한다고 했을 때, 왼쪽의 방법을 쓰면 5가지의 알파에 대해 훈련하게 되지만, 오른쪽 방법을 쓰면 25가지의 알파 값에 대해 훈련할 수 있다.
어떤 하이퍼파라미터가 가장 핵심적이든 그 하이퍼파라미터의 여러 값에 대해 훈련할 수 있다.
2. 정밀화 접근 방식
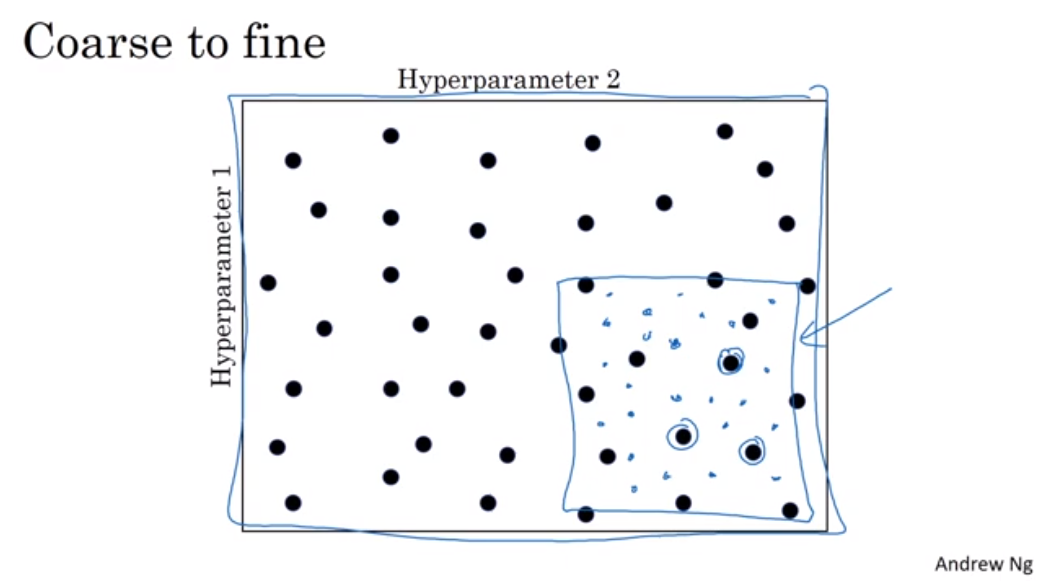
전체 공간에서 탐색한 후, 성능이 좋은 구역이 있다면 그 구역 안에서 정밀하게 탐색하는 방법이다.
적절한 척도 선택하기
‘무작위’가 모든 값들 중 공평하게 뽑는다는 뜻은 아니다. 적절한 척도를 선택하는 것이 중요하다.
무작위로 뽑는 게 좋은 하이퍼파라미터
은닉 유닛의 수, 은닉층의 수
→ 무작위, Grid search 모두 가능
척도가 필요한 하이퍼파라미터
- 학습률 알파

예) 알파를 0.0001~1 사이의 값으로 설정할 때, 일반적인 선형 척도를 이용하면 오직 10%의 값만 0.0001~0.1 사이에 존재한다.
→ 로그 척도를 이용해 균일한 비율이 나오도록 한다.
r = -4 * np.random.rand() # 지수를 랜덤하게 구함
a = math.pow(10, r)- 지수 가중 이동 평균에서 사용되는 β
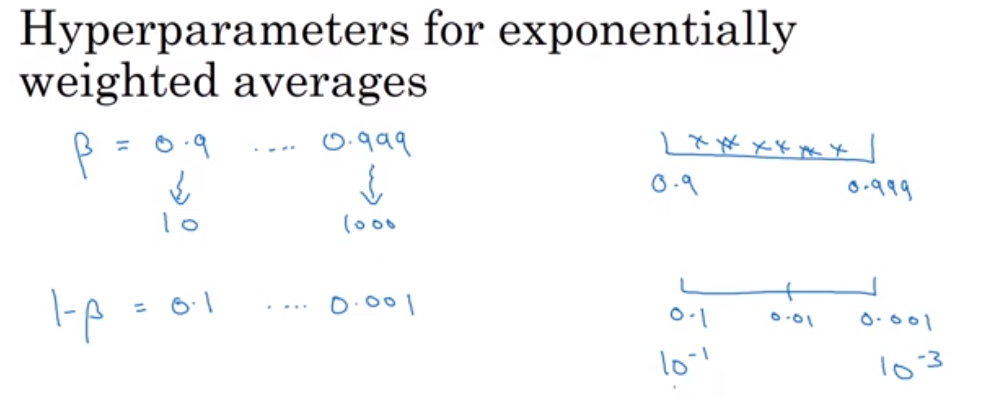
베타는 0.9와 0.999 사이의 값인데, 앞과 같이 균일한 범위에서 탐색하기 위해 로그 척도를 이용한다. 다만, 1-베타를 튜닝해 0.1~0.001 사이의 값을 찾는다.
척도를 완벽하게 설정하지 않아도, 정밀화 접근 방식을 사용하면 좋은 하이퍼파라미터를 찾을 수 있다.
실습
하이퍼파라미터를 찾는 과정은 NLP, CV, logistics 등 딥러닝의 분야에 개별적으로 적용된다. 즉, 과거에 찾은 파라미터가 다른 분야에서 잘 작동하지는 않을 수 있다. 다시 테스트하여 확인해야 한다.
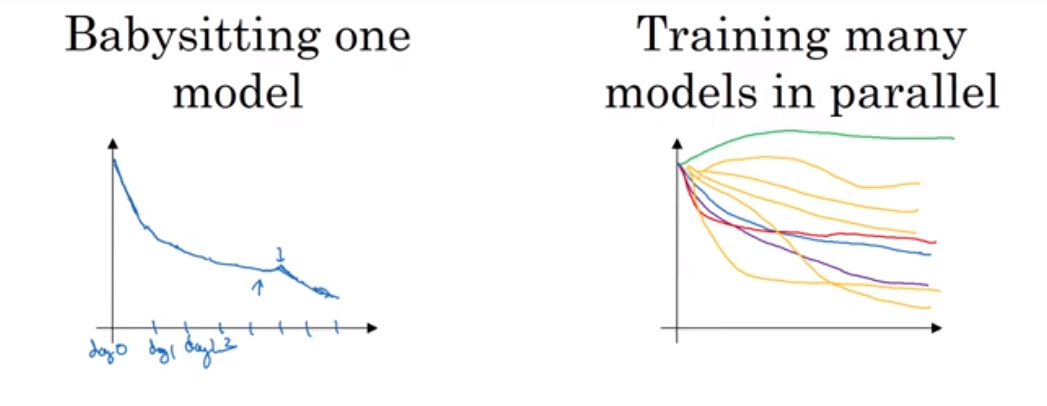
1. Babysitting one model, 판다 접근
컴퓨터의 자원이 많이 필요하지 않거나, 적은 숫자의 모델을 한 번에 학습시킬 수 있을 때 사용한다. 하나의 모델로 매일 성능을 지켜보면서, 학습 속도를 조금씩 바꾸는 방식이다. 온라인 광고, CV 앱과 같이 많은 데이터를 필요로 해서 모델의 크기가 크면 판다 접근을 주로 사용한다.
2. 병렬적으로 여러 모델 훈련, 캐비어 접근
충분한 컴퓨터 자원을 가지고 있다면 사용한다. 다양한 하이퍼파라미터를 테스트할 수 있다.
부스트코스에서 앤드류 응 교수님의 강의를 듣고 정리한 내용입니다.
'AI' 카테고리의 다른 글
| 🔍 추천 시스템 종합 정리 - 구조, 종류, 한계, 검색 시스템과의 차이 (1) | 2025.01.29 |
|---|---|
| 🏛️ [딥러닝 2단계] 6. 배치 정규화(Batch Normalization) (3) | 2025.01.07 |
| 🖌️ [딥러닝 2단계] 3. 최적화 문제 설정 (1) | 2025.01.07 |
| 📈 [딥러닝 2단계] 2. 신경망 네트워크의 정규화 (3) | 2025.01.07 |
| 🖍️ [딥러닝 2단계] 1. 머신러닝 어플리케이션 설정하기 (0) | 2025.01.07 |



