
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 18405
- google dialogflow
- 알고리즘
- 추천과 검색
- 3085
- 파이썬
- Pypy3
- 특정 거리의 도시 찾기
- 추천시스템
- 경쟁적 전염
- 앤드류 응
- hannanum
- 10825
- 유사도
- 14620
- 1259
- 컨텐츠 기반 필터링
- 구조적 데이터
- 문자열반전
- 유튜브 추천 시스템
- 협업 필터링
- 7785
- 18352
- 넷플릭스 추천 시스템
- 1620
- 추천 시스템의 한계
- 7662
- 백준
- 추천 시스템
- python
- Today
- Total
Kowal's Igloo
🔍 추천 시스템 - Youtube와 Netflix의 추천 시스템, 최근 이슈 본문
주요 기업별 추천 시스템
Youtube
유튜브의 추천 시스템은 고려해야 할 3가지 주요 문제가 있다.
- Scale: 유튜브 비디오의 규모가 압도적으로 크기 때문에 일반적인 추천 알고리즘이 동작하기 어려운 수준이라는 것
- Freshness: 매 초마다 새로 업로드되는 많은 영상을 고려할 수 있어야 한다는 것
- Noise: 플랫폼에 있는 영상의 규모에 비해 유저의 반응이 부족한데, 그마저도 데이터로 관찰하기 어려운 요소에 의한 행동이나 필요 없는 행동이 포함된다는 것
- 2016 (Candidate Generation 모델과 랭킹 모델)
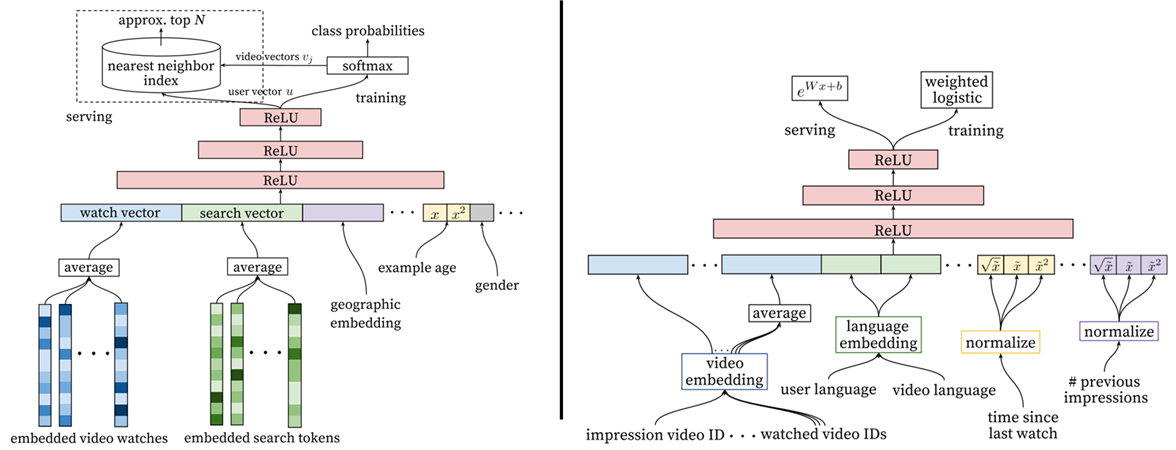
- 2019 (랭킹 모델만)

2016년에는 전형적인 Multi-Stage 모델(후보 찾고 순위 매기기)을 사용했다.
2019년에는 고도화된 추천을 위해 랭킹 모델을 개선하는 데에 초점을 맞췄다. 보통 딥러닝 분야에서는 모델의 성능을 높이기 위해 다수의 레이어로 구성된 깊은 모델 구조를 만드는 것이 대표적인 방법이지만, 속도가 느려지기 때문에 실시간으로 추천 목록을 제공하기 위해서는 얕은 모델로 구성해야 한다.
따라서 모델의 레이어를 크게 늘리지 않으면서도 효과적으로 학습하기 위해 2019년에 새롭게 제안된 방법은 다음 3가지이다.
- multi-task 학습 목표 설정
- 하나의 모델로 여러 가지 정보를 학습하는 방식
- 정답 데이터를 직접적으로 적용하기 어려울 때 사용
- 두 가지 목표: 참여도(추천된 비디오 클릭 및 시청 여부), 만족도(’좋아요’ 등)
- multi-task learning에 효율적인 모델 구조 도입
- feedback loop에서 발생하는 selection bias 처리
- feedback loop: 유저가 진심으로 원하는 것이 아닌 시스템이 추천한 목록 중에서 선택한다는 것
- 기존 시스템으로부터 데이터가 도출되기에 새로운 모델도 기존 시스템에 편향된다는 문제 발생
- 특히 추천 목록의 처음 위치를 습관적으로 클릭하는 경향이 있는데, 영상 노출 위치 같은 별도의 feature를 추가함 → 잘 보이는 위치에 노출된 콘텐츠를 시청하는 것보다 잘 안 보이는 위치에 노출된 콘텐츠를 시청했을 때 해당 콘텐츠에 높은 점수를 부여하는 방식
Netfilx
넷플릭스는 2015년 9개의 추천 알고리즘을 발표했다. 아래는 그중 핵심 알고리즘 4가지이다.
- 개인별 인기 추천 (Personal Video Ranker)
- 콘텐츠에 대한 이용자의 예상 별점을 계산해 높은 순으로 보여주는 알고리즘
- 협업 필터링과 컨텐츠 기반 필터링을 복합적으로 사용
- 인기 콘텐츠 추천 (Top-N Video Ranker)
- 특정 기간 동안 많이 시청된 순으로 추천
- 좋아요 많은, 댓글 많은 등으로 확장 가능
- 다른 메타데이터를 활용하기도 함 (예) 제작 국가 - 한국에서 가장 많이 시청한)
- feedback loop 해결
- 콘텐츠가 노출된 위치에 따라 집계되는 시청 건수에 가중치를 부여
- 시청의 몰입 정도(시청 중단 위치)로 필터링 (예) 시청 중단 위치가 5%라면 랭킹에 반영하지 않음)
- Trending Now
- 특정 시기에 나타나는 콘텐츠 소비 패턴을 분석하여 추천
- 예) 발렌타인데이 전후로 로맨틱 영화를 많이 보는 경향
- 페이지 제너레이션
- 여러 콘텐츠를 나란히 묶어 하나의 블록(row)을 만들고, 이렇게 구성된 여러 개의 블록을 화면에 노출하는 알고리즘
- PVR, Top-N, 트렌딩나우와 같은 알고리즘으로 만들어진 블록 중 이용자에게 노출할 블록을 최종적으로 결정하는 알고리즘
- Fixed(항상 고정적으로 노출), Movable but Mandatory(높은 확률로 노출되지만 선호도에 따라 위치 변경), Movable but Optional(이용자의 선호도에 따라 블록을 노출하거나 노출하지 않음)
최근 이슈
- 개인정보 활용 문제 - 네이버 뉴스 추천 AiRS 알고리즘
- 네이버가 자체 인공지능(AI)을 이용해 뉴스 추천 서비스를 제공하면서 개인정보를 무단 활용하고 있다는 논란이 제기됨
- ‘서비스 이용과정에 자동생성되는 정보’를 AI에 활용하는데, 범위가 정확히 명시되지 않았다는 문제점
- 사용자를 특정 정치 키워드별로 묶었다가 데이터가 유출될 경우 사회적 낙인이 찍힐 우려
https://www.yna.co.kr/view/AKR20241014073500017
"동의 안 했는데"…네이버, 개인정보 뉴스추천 활용 적법성 논란 | 연합뉴스
(서울=연합뉴스) 최현석 노재현 기자 = 네이버가 자체 인공지능(AI)을 이용해 뉴스 추천 서비스를 제공하면서 개인정보를 무단 활용하고 있다는 ...
www.yna.co.kr
- 메타
- '생성 검색(Generative retrieval)'은 사용자가 과거에 상호작용한 아이템을 바탕으로 다음에 추천할 아이템을 예측하는 새로운 방식이다. 이 방법은 데이터베이스를 직접 검색하지 않고도 사용자의 의도를 이해하고 추천할 수 있게 해준다.
- 라이거는 생성 검색의 계산 효율성과 밀집 검색의 강력한 임베딩 품질을 결합, 효과적인 추천을 제공하도록 설계됐다. 훈련 단계에서 라이거는 유사도 점수와 다음 토큰 예측을 함께 활용해 모델의 추천 품질을 향상시킨다. 이어 추론 단계에서는 생성 메커니즘을 통해 여러 후보 아이템을 선택하고, 콜드 스타트 항목을 추가해 최종 추천을 제공한다.
Meta AI Proposes LIGER: A Novel AI Method that Synergistically Combines the Strengths of Dense and Generative Retrieval to Signi
Recommendation systems are essential for connecting users with relevant content, products, or services. Dense retrieval methods have been a mainstay in this field, utilizing sequence modeling to compute item and user representations. However, these methods
www.marktechpost.com
https://www.aitimes.com/news/articleView.html?idxno=166863
메타, '추천 알고리즘'에 생성 AI 결합한 새로운 방법 공개 - AI타임스
메타가 생성 인공지능(AI)을 기존 추천 알고리즘에 통합한 새로운 추천 시스템을 선보였다. 생성 AI를 추천 알고리즘에 결합한 것은 처음으로, 이를 통해 사용자 의도를 더 효과적으로 파악할 수
www.aitimes.com
참고 자료
'AI' 카테고리의 다른 글
| 🔍 추천 시스템 종합 정리 - 구조, 종류, 한계, 검색 시스템과의 차이 (1) | 2025.01.29 |
|---|---|
| 🏛️ [딥러닝 2단계] 6. 배치 정규화(Batch Normalization) (3) | 2025.01.07 |
| 🍎 [딥러닝 2단계] 5. 하이퍼파라미터 튜닝 (0) | 2025.01.07 |
| 🖌️ [딥러닝 2단계] 3. 최적화 문제 설정 (1) | 2025.01.07 |
| 📈 [딥러닝 2단계] 2. 신경망 네트워크의 정규화 (3) | 2025.01.07 |



